
Derrière chaque modèle qui prédit si un client va partir, si un email est un spam ou si un patient présente un risque, on retrouve souvent le même algorithme discret : la régression logistique. Sobre, interprétable et redoutablement efficace, elle reste aujourd'hui l'un des outils les plus utilisés en apprentissage automatique.
Comprendre la régression logistique
Définition et concepts clés
Modéliser la probabilité qu'un événement survienne en fonction de variables indépendantes : tel est le cœur de la régression logistique.
Contrairement aux méthodes de régression classiques qui prédisent une valeur continue, cette technique est conçue pour les résultats binaires — oui ou non, succès ou échec, clic ou absence de clic. Plutôt que de produire un chiffre brut, elle estime une probabilité comprise entre 0 et 1, ce qui la rend directement interprétable. Un score de 0,85 signifie que l'événement a 85 % de chances de se produire selon les variables observées. Cette propriété en fait un outil particulièrement adapté aux problèmes de classification, là où la frontière entre deux états doit être tracée avec précision.
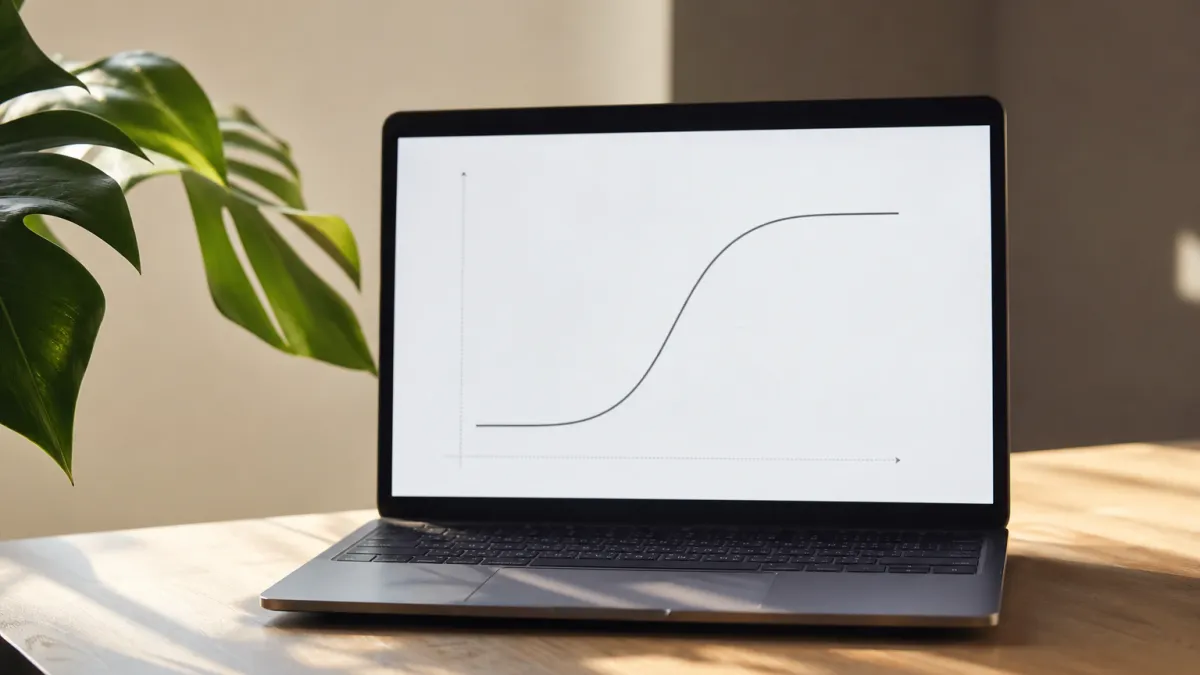
Fonctionnement mathématique
La fonction sigmoïde transforme une combinaison linéaire de variables en une valeur comprise entre 0 et 1, interprétable directement comme une probabilité. Concrètement, plus la somme pondérée des variables d'entrée est élevée, plus la courbe en S pousse la probabilité vers 1 — et inversement. Ce mécanisme garantit que le modèle ne produira jamais de valeur aberrante, quelle que soit l'amplitude des données d'entrée.
Avantages et limites
Sa capacité à produire des probabilités directement interprétables constitue l'un des atouts les plus concrets de cette méthode — un score de 0,82 signifie immédiatement "82 % de chances", sans conversion supplémentaire. Cette lisibilité facilite la prise de décision opérationnelle, notamment pour les équipes non techniques.
Plusieurs caractéristiques méritent d'être pesées avant de déployer le modèle :
- Sorties probabilistes directes : chaque prédiction exprime une vraisemblance chiffrée, ce qui permet de calibrer des seuils de décision adaptés au contexte métier.
- Interprétabilité des coefficients : chaque variable contribue de façon transparente au résultat, facilitant l'audit et la communication aux parties prenantes.
- Légèreté computationnelle : l'entraînement reste rapide même sur des jeux de données volumineux, contrairement à des algorithmes plus complexes.
- Hypothèse de linéarité : le modèle suppose une relation linéaire entre les prédicteurs et le log-odds ; si cette condition n'est pas vérifiée dans les données, les performances se dégradent sensiblement.
- Sensibilité aux variables corrélées : la multicolinéarité entre prédicteurs gonfle l'incertitude des coefficients et peut fausser l'interprétation.
Applications concrètes de la régression logistique
Comprendre les mécanismes d'un modèle, c'est bien. Voir où il s'applique dans des contextes réels, c'est là que la méthode prend tout son sens.
Utilisation en marketing
En marketing, la régression logistique permet d'estimer la probabilité qu'un client achète un produit après avoir été exposé à une publicité. À partir de variables comme l'historique d'achat, le comportement de navigation ou les données démographiques, le modèle attribue un score individuel à chaque prospect. Les équipes marketing peuvent ainsi concentrer leurs budgets sur les segments les plus susceptibles de convertir, plutôt que de diffuser des campagnes à l'aveugle. Ce ciblage probabiliste réduit le coût d'acquisition tout en améliorant le taux de conversion.
Applications en santé
Dans le domaine médical, prédire la probabilité qu'un patient développe une maladie à partir de ses facteurs de risque constitue l'un des usages les plus documentés de cette méthode. Âge, antécédents familiaux, résultats biologiques : chaque variable alimente le modèle pour produire un score de risque individuel, directement exploitable en prévention.
| Domaine | Application |
|---|---|
| Santé | Évaluation des risques de maladies |
| Marketing | Prédiction du comportement des consommateurs |
| Finance | Analyse des risques de crédit |
| Médecine d'urgence | Triage et priorisation des patients |
| Épidémiologie | Identification des populations vulnérables |
Techniques avancées et variations
Au-delà des cas binaires explorés jusqu'ici, la régression logistique se décline en plusieurs variantes qui étendent considérablement son champ d'action face à des problèmes plus complexes.
Régression logistique multinomiale
Dès que la variable cible dépasse deux catégories — choisir entre plusieurs tranches d'âge, plusieurs types de produits ou plusieurs profils de clients —, la version binaire du modèle atteint ses limites. La régression logistique multinomiale prend alors le relais : elle modélise simultanément la probabilité d'appartenir à chacune des catégories, en comparant chaque modalité à une classe de référence. Les enquêtes d'opinion, où les répondants choisissent parmi plusieurs options distinctes, constituent un terrain d'application particulièrement naturel pour cette extension.
Régression logistique ordinale
Certaines variables résistent à la classification binaire ou nominale : noter sa satisfaction de « faible » à « élevée », classer un risque de crédit de « bas » à « critique », évaluer un niveau de douleur de 1 à 10. La régression logistique ordinale est précisément conçue pour ces situations, où les catégories suivent un ordre naturel mais où les écarts entre elles ne sont pas nécessairement uniformes. Elle modélise alors la probabilité cumulée de dépasser chaque seuil successif.
Techniques de régularisation
Entraîner un modèle sur des données trop nombreuses ou trop corrélées expose à un risque bien documenté : le surapprentissage, où l'algorithme colle si précisément aux exemples d'entraînement qu'il perd toute capacité de généralisation. Les techniques de régularisation Lasso et Ridge répondent directement à ce problème en ajoutant une pénalité mathématique à la fonction de coût du modèle. Ridge contraint les coefficients à rester faibles sans les annuler, préservant toutes les variables dans l'équation. Lasso, lui, pousse certains coefficients exactement à zéro, produisant ainsi une sélection automatique des variables les plus pertinentes. Le choix entre les deux dépend du contexte : Ridge convient aux situations où toutes les variables contribuent, Lasso s'impose dès que la parcimonie du modèle est recherchée.
Outil discret mais redoutablement efficace, la régression logistique reste aujourd'hui l'une des méthodes les plus déployées dans l'analyse de données. Sa lisibilité des résultats en fait un pont naturel entre la modélisation statistique et la prise de décision concrète — un atout rare que peu d'algorithmes plus complexes peuvent revendiquer.
Questions fréquentes
C'est quoi la régression logistique en termes simples ?
La régression logistique est un algorithme de classification qui prédit la probabilité qu'un événement se produise — par exemple, qu'un client achète ou non un produit — en s'appuyant sur une ou plusieurs variables explicatives.
Quelle est la différence entre régression logistique et régression linéaire ?
La régression linéaire prédit une valeur continue (un prix, une température), tandis que la régression logistique prédit une probabilité entre 0 et 1, adaptée aux variables cibles binaires comme oui/non ou vrai/faux.
Quand utiliser la régression logistique plutôt qu'un autre modèle ?
Elle est idéale lorsque la variable à prédire est binaire, que les données sont relativement linéairement séparables et que l'interprétabilité du modèle est prioritaire — en médecine, en marketing ou en scoring de crédit, par exemple.
Comment interpréter les coefficients d'une régression logistique ?
Chaque coefficient représente l'effet d'une variable sur le log-odds de l'événement. En l'exponentiant, on obtient un odds ratio : une valeur supérieure à 1 indique que la variable augmente la probabilité de l'événement.
Quelles sont les limites de la régression logistique ?
Elle suppose une relation linéaire entre les variables et le log-odds, gère mal les relations complexes ou non linéaires, et peut être mise en difficulté par la multicolinéarité ou un déséquilibre important des classes.